树
数是一种典型的非线性的数据存储结构,与链表类似,但却不同,因为树的一个节点可以指向多个节点。
- 部分术语
- 叶子结点:没有孩子节点的节点叫做叶子节点
- 节点的深度:从根节点到该节点的路径长度
- 节点的高度:是指从该结点到最深结点的路径长度
- 斜树:如果树中除了叶子节点外,其余每一节点只有一个孩子节点,这种树称作斜树。
二叉树
一棵树中每个节点只有0,1或2个孩子节点,那么这棵树称为二叉树。
-
类型
-
严格二叉树:每个节点要么有两个孩子节点,要么没有孩子节点
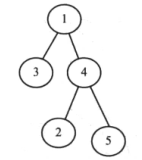
-
满二叉树:二叉树中每个结点恰好有两个孩子结点且所有叶子结点都在同一层
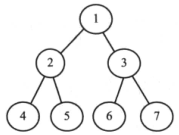
-
完全二叉树:假定二叉树的高度为h,所有结点从根节点开始从左到右,从上之下,依次编号,那么将得到1到n的完整序列。所有叶子节点的深度为h或h-1,且在结点编号序列中没有漏电任何数字,这样的二叉树称为完全二叉树。
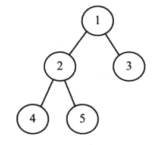
-
-
性质
- 满二叉树的结点个数n为2^(h+1)-1
- 完全二叉树的结点个数为2^h ~ 2^(h+1)-1
- 满二叉树的叶子节点个数是2^h
- 对于n个结点的完全二叉树,空指针的个数为n+1
-
结构
定义两个指针,分别指向左右子树
public class BinaryTreeNode{ private int data; private BinaryTreeNode left; private BinaryTreeNode right; //getter,setter方法 //...... } -
应用
- 编译器中表达式树
- 用于数据压缩算法中赫夫曼编码树
- 支持在集合中查找,插入和删除,其平均时间复杂度为O(logn)的二叉搜索树
- 优先队列(PQ)支持以对数时间(最坏情况下)对集合中的最小(或最大)数据元素进行搜索和遍历
-
遍历
- 前序遍历:先遍历当前结点,然后遍历左子树,最后遍历右子树
- 中序遍历:首先遍历左子树,再访问当前结点,最后遍历右子树
- 后续遍历:首先遍历左子树,再遍历右子树,最后访问当前结点
- 层序遍历:按层遍历,这是一种广度优先遍历方法
遍历实现
前序遍历
//递归版本,时间复杂度为O(n),空间复杂度为O(n)
void PreOrder(BinaryTreeNode root) {
if(root != null) {
System.out.println(root.getData());
PreOrder(root.getLeft());
PreOrder(root.getRight());
}
}
//非递归版本,时间复杂度为O(n),空间复杂度为O(n)
//采用一个栈进行记录
void PreOrderNonRecursive(BinaryTreeNode root) {
if(root == null) return null;
LLStack S = new LLStack();
while(true) {
while(root!=null) {
System.out.println(root.getData);
S.push(root);
root = root.left;//遍历左子树
}
if(S.isEmpty()) break;
root = (BinaryTreeNode)S.pop();
root = root.getRight();
}
return;
}
中序遍历
//递归版本
void InOrder(BinaryTreeNode root) {
if(root != null) {
InOrder(root.getLeft());
System.out.println(root.getData());
InOrder(root.getRight());
}
}
//非递归版本
void InOrderNonRecursive(BinaryTreeNode root) {
if(root == null) return null;
LLStack S = new LLStack();
while(true) {
while(root != null) {
S.push(root);
root = root.getLeft();
}
if(S.isEmpty()) break;
root = (BinaryTreeNode)S.pop();
System.out.println(root.getData());
root = root.getRight();
}
return;
}
后序遍历
void PostOrder(BinaryTreeNode root) {
if(root != null) {
PostOrder(root.getLeft());
PostOrder(root.getRight());
System.out.println(root.getData());
}
}
//非递归版本
//后序遍历的非递归版本:要解决当前结点要被访问两遍
void PostOrderNonRecursive(BinaryTreeNode root) {
LLStack S = new LLStack();
while(1) {
if(root!=null) {
S.push(root);
root = root.getLeft();
} else {
if(S.isEmpty()) {
System.out.println("Stack is Empty");
return;
} else {
if(S.top().getRight() == null) {
//右子树不存在时
root = S.pop();
System.out.println(root.getData());
if(root == S.top().getRight()) {
System.out.println(S.top().getData());
s.pop();
}
}
if(!S.isEmpty()) root = S.top().getRight();
else root = null;
}
}
}
}
问题
对于树的问题,一般可以通过递归方法解决,采取非递归方法,可以采用队列存储元素。时间复杂度和空间复杂度均为O(n)。
-
删除树?
删除树一般采取后序遍历的方法,先删除孩子结点,再删除双亲结点。
void DeleteBinaryTree(BinaryTreeNode root) { if(root == null) return; DeleteBinaryTree(root.getLeft()); DeleteBinaryTree(root.getRight()); root = null;//置为null,GC会对其进行清理 } -
逐层输出树中的元素,如下图所示,输出应为4 5 6 7 2 3 1

解题思路:借助队列可以遍历每一层元素,通过栈可以输出每一层(从下往上)的元素
void LevelOrderTraversalInreverse(BinaryTreeNode root) { LLQueue Q = new LLQueue(); LLStack S = new LLStack(); BinaryTreeNode temp; if(root == null) return; Q.enQueue(root); while(!Q.isEmpty()) { temp = Q.deQueue(); if(temp.getRight()) { Q.enQueue(temp.getRight()); } if(temp.getLeft()) { Q.enQueue(temp.getLeft()); } S.push(temp); } while(!S.isEmpty()) { System.out.println(S.pop().getData()); } } -
将一颗树转换成其镜像?判断两棵树是否为镜像对称?
BinaryTreeNode MirrorOfBinaryTree(BinaryTreeNode root) { BinaryTreeNode temp; if(root) { MirrorOfBinaryTree(root.getLeft()); MirrorOfBinaryTree(root.getLeft()); //交换两个结点 temp = root.getLeft(); root.setLeft(root.getRight()); root.setRight(temp); } //以上if条件里面还可以优化,再判断是否有左右子树,再执行迭代 } //判断两棵树是否镜像 int AreMirrors(BinaryTreeNode root1, BinaryTreeNode root2) { if(root1 == null && root2 == null) { return 1; } if(root1 == null || root2 == null) { return 0; } if(root1.getData()!=root2.getData()) { return 0; } else { return AreMirrors(root1.getLeft(), root2.getRight()) && AreMirrors(root1.getRight(), root2.getLeft()); } } -
根据中序遍历和前序遍历结果构建一颗二叉树。
前序遍历的顺序:根结点,左结点,右结点;中序遍历的顺序:左结点,根节点,右结点。
BinaryTreeNode BuildBinaryTree(int inOrder[], int preOrder[], int inStrt, int inEnd) { static int preIndex = 0; BInaryTreeNode newNode = new BinaryTreeNode(); if(inStrt > inEnd) return null; if(newNode == null) { System.out.println("Memory Error"); return null; } //利用preIndex在前序遍历中选择当前节点 newNode.setData(preOrder[preIndex]); preIndex++; if(inStrt == inEnd)//该节点没有孩子结点返回 return newNode; //否则在中序遍历中找到该节点的索引 int inIndex = Search(inOrder, inStrt, inEnd, newNode.getData()); //构建左右子树 newNode.setLeft(BuildBinaryTree(inOrder, preOrder, inStrt, inIndex-1)); newNode.setRight(BuildBinaryTree(inOrder, preOrder, inIndex+1, inEnd)); } -
给定两个遍历序列能否构建一颗唯一的二叉树?
- 中序和前序
- 中序和后序
- 中序和层次遍历
-
寻找两个结点的最近公共祖先(LCA)。
BinaryTreeNode LCA(BinaryTreeNode root, BinaryTreeNode a, BinaryTreeNode b) { BinaryTreeNode left, right; if(root == null) return root; if(root == a || root == b) { return root; } left = LCA(root.getLeft(), a, b); right = LCA(root.getRight(), a, b); if(left && right) return root; else return left ? left: right; }
其他类型树
二叉搜索树
二叉搜索树有以下性质:
- 一个结点的左子树只能包含键值小于该节点键值的结点
- 一个结点的右子树只能包含键值大于该节点键值的结点
- 左子树和右子树都必须是二叉搜索树
//二叉搜索树插入元素
BinarySearchTreeNode Insert(BinarySearchTreeNode root, int data) {
if(root == null) {
root = new BinarySearchTreeNode();
if(root == null) {
System.out.println("Memory error");
return;
} else {
root.setData(data);
root.setLeft(null);
root.setRight(null);
}
} else {
if(data < root.getData()) {
root.setLeft(Insert(root.getLeft(), data));
} else if(data > root.getData()) {
root.setRight(Insert(root.getRight(), data))
}
}
}
//二叉搜索树删除元素
//想法从删除元素的左子树寻找最大值取代当前删除元素,或者从右子树中寻找最小值来取代
BinarySearchTreeNode Delete(BinarySearchTreeNode root, int data) {
BinarySearchTreeNode temp;
if(root == null)
System.out.println("Element not there in tree");
else if(data < root.data)
root.left = Delete(root.getLfet(), data);
else if(data > root.data)
root.right = Delete(root.getRight(), data);
else {
if(root.getLeft() && root.getRight()){
temp = FindMax(root.getLeft());
root.setData(temp.getData());
root.setLeft(Delete(root.getLeft(), root.getData()));//删除temp节点
} else{
temp = root;
if(root.getLeft() == null)
root = root.getRight();
if(root.getRight() == null)
root = root.getLeft();
temp = null;
}
}
}
二叉查找(搜索)树的中序遍历的结果是一个递增序列。
平衡二叉树
平衡因子k:左右子树的高度差。
当k=0时,二叉搜索树叫做完全平衡二叉树。
AVL树
当平衡因子为1时,这样的二叉搜索树叫做AVL树。AVL树是一种平衡二叉树,左右子树的高度差小于等于1,其每一个子树均为也为平衡二叉树
- AVL树和红黑树的区别
- 查找上:AVL树比红黑树更平衡,因此AVL树的查找效率更高
- 插入上:AVL树插入之后,要更新平衡因子,对新节点的路径(可能会延续到根节点)进行调整,过于繁琐;对于红黑树,则只需要通过变色减少很多旋转操作。总的来讲,红黑树插入要比AVL树好很多。
- 删除上:AVL树删除后,某子树的深度必然减少,此时又要重新调整保证整颗树的平衡;而红黑树只需要在少数情况下,要重新平衡父节点,大部分以变色操作为主,所以红黑树的删除操作也要比AVL树好很多。
红黑树
首先先谈谈二叉查找树的特性:1. 左子树上所有结点的值小于或等于它的根节点的值;2. 右子树上所有结点的值均大于或等于它的根节点的值;3. 左右子树均为二叉排序树。但二叉查找树存在一个缺点,但出现极度不平衡的情况时,二叉查找树会变成线性结构,这就会使二叉查找树的查找特性大打折扣。
红黑树则是一种自平衡的二叉查找树(但又不是严格的平衡二叉搜索树,因为左右子树的高度差并不确定),除了符合二叉查找树的特性外,还需满足一下特性:
- 结点是红色或黑色
- 根节点是黑色
- 每个叶子节点都是黑色的空节点
- 每个红色结点的两个子节点都是黑色
- 从任一结点到其每个叶子所有路径都包含相同数目的黑色结点
为了维持红黑树的平衡,插入新元素后如果破坏了原来的特性,需要进行“变色”和“旋转(左旋转和右旋转)”两个操作。变色和旋转的操作,还真的挺复杂,没有具体的方法,一般操作流程:变色->左旋转->变色->右旋转->变色。
应用在TreeSet和TreeMap,Java8中HashMap采用红黑树实现。
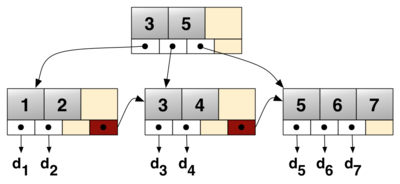
B树
B树是一种自平衡多路查找树,能够保持数据有序,查找数据,顺序访问,插入和删除数据均可以在对数时间内完成,B树的一个节点至少拥有两个子节点。B树常用在文件系统中,可以减少定位记录提高存取速度,由于有多路子节点,降低了树的的高度,减少磁盘IO操作。
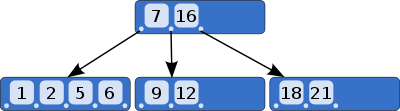
B+树
B+树是基于B树基础上,充分利用节点的空间,提高了查找效率。B+树与B树的区别在于:
- 非叶子节点不保存关键字记录指针,只进行数据索引,因此每个非叶子节点多能保存的信息更多了。
- B+树中所有关键字记录均存放在叶子节点中,因此所有数据都必须到了叶子节点才能查看。
- B+树叶子左边数据结尾会指向右边数据节点开始(这样有利于数据库的select操作在同一层获取多条数据,而不必像B树还得跨层重新获取)。
这里附上一个数据库的索引解析的文章