1. 转发(Forward)和重定向(Redirect)的区别?
转发是服务器行为,重定向是客户端行为
转发通过RequestDispather的forward方法进行转发,跳转到新的页面,但是浏览器并不知道,所以地址栏的URL不会更新。
重定向则是利用HTTP响应状态码实现的。服务器通过HttpServletRequestResponse的setStatus方法设置状态码,返回给浏览器301或者302,浏览器根据得到新的网址重新发起请求,地址栏同时也会刷新为新的url。
两者不同的地方有:
- 地址栏显示的地址会有所更新。
- 数据共享:转发可以共享request中数据到新页面,而重定向则不可以。
- 转发常用在用户登录跳转到相应模块,而重定向则是用在用户注销返回主页和跳转到别的网站常用到。
- 效率方面,转发更高,在服务器完成一切操作。
2. 关于数据库索引的问题?
使用索引的优点:
- 通过创建唯一性索引可以保证数据库每一行数据的唯一性
- 可以加快数据检索的速度(大大减少检索的数据量)
- 可以帮助服务器避免排序和临时表
- 将随机IO变为顺序IO
- 可以加速表和表之间的连接
缺点:
- 对数据增删改时,也要对索引进行动态维护,减低数据的维护速度
- 索引会占据物理空间,如果建立聚簇索引会占据更大的物理空间
- 创建和维护索引需要耗费时间,而且随着数量的增加,时间也会变长
索引提高查询速度是通过将无序的数据转换成有序的数据。
使用索引的注意事项:
- 避免在where子句中对字段施加函数,以免造成无法命中索引
- InnoDB中使用与业务无关的自增主键作为主键(逻辑主键),不要使用业务主键
- 对需要加索引的列设置为NOT NULL,否则会导致引擎放弃使用索引进而采用全表扫描
- 定时删除长期未使用的索引以造成不必要的性能损耗,可通过sys库的chema_unused_indexes视图来查询哪些索引不被使用
- 使用limit offset查询缓慢时,可借助索引提高查询性能
MySQL中索引主要使用的两种数据结构
- 哈希索引:由名字可以知道,底层的数据结构为哈希表
- BTree索引:数据为B+树,对于InnoDB和MyISAM的两种引擎实现的方式是不同
对于单条记录查询时,可以采用哈希索引,查询性能最快;对于其他大部分场景,建议选择BTree索引。
覆盖索引:是指一个索引包含或者覆盖了所需要查询字段的值,称之为覆盖索引。
3. 进程和线程相关
进程和线程间的区别
进程是资源调度和分配的独立单元,线程则是调度和执行的独立单元;进程间切换代价大,而同一进程内不同线程切换代价小;进程拥有更多的资源,线程拥有的资源很少。
进程间的通信方式:
- 管道(pipe):半双工的通信方式,数据只允许单向流动,一般只用在父子进程间。
- 命名管道(fifo):同样也是半双工通信方式,但允许无亲缘关系的进程相互通信。
- 信号量(semophore):是一种计数器,控制多个进程对共享资源的访问,其实也就是锁机制,用于资源同步。
- 消息队列(message queue):消息队列是由消息组成的链表,存放于内科中,有消息队列标识符标识,克服管道只能承载无格式字节流以及缓冲区大小有限,可以接受的消息类型多样。
- 信号(signal):用于通知进程某一事件已经发生。
- 共享内存(shared memory):就是映射一段可以共享被其他进程访问的内存,共享内存是最快的IPC方式,针对其他进程间的通信方式运行效率低专门设计的,可与其他方式配合使用。
- 套接字(socket):也是一种进程的通信方式,可用于不同主机的不同进程间的通信。
线程间的通信方式:
- 锁机制:互斥锁、读写锁和条件变量
- 信号量机制
- 信号机制
4. SpringMVC的原理
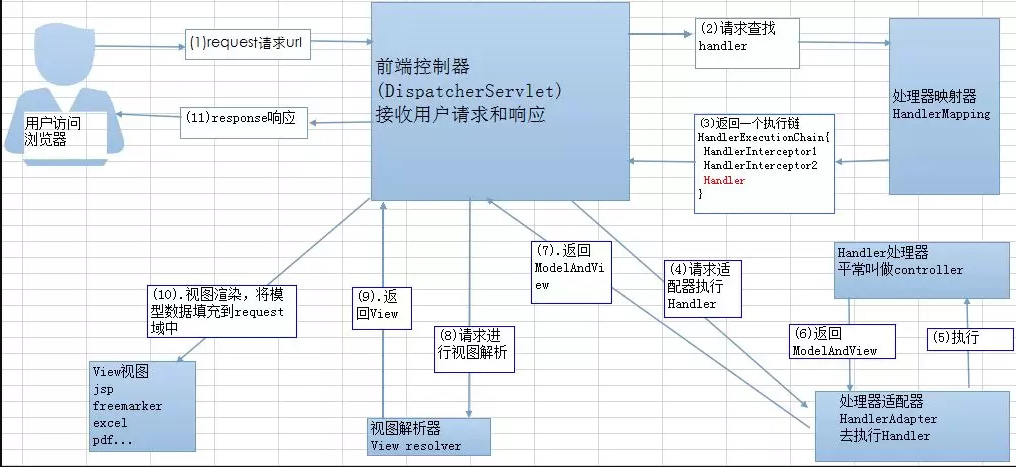
- 客户端向服务器发送请求,前端控制器DispatcherServlet接受请求,查找合适的解析请求的handler
- 查找到合适的Handler之后HandlerAdapter会调用controller处理请求和处理相应的业务逻辑
- 处理完成之后,controller会返回一个模型视图ModelAndView
- 视图解析器会对这个ModelAndView进行解析,返回一个视图对象
- 前端控制器DispatherServlet会填充数据到视图对象上
- 最后将页面返回给客户端浏览器。
5.SpringAOP和IOC实现原理
IOC:控制反转,更简单易懂的概念是依赖注入(DI)。通过Java的反射机制实现,将所有对象交由给容器进行管理,只需要在Spring配置文件配置对应的bean及其属性,然后容器就会根据配置文件将bean初始化好,在需要调用的时候,把初始化的bean分配需要的地方。
AOP:面向切面编程,主要利用代理实现。一种是采用动态代理,在动态运行期间,对消息进行装饰,以取代原有对象行为的执行;另外一种则是静态代理,通过注解一类特殊的书法,在编译期间织入相关代码。
6. 关于消息队列
消息队列的作用:
- 通过异步处理提高系统性能,可以借助消息队列对数据库操作进行缓冲,降低并发访问高峰
- 降低系统的耦合性,利用发布-订阅模式,生产者通过消息队列向一个或多个消息订阅者发送消息。新增业务,可以通过订阅消息来获取,而对于原系统和业务无影响,从而实现了网站的可扩展性。
消息队列带来的问题:
- 消息丢失或MQ所在的机器挂掉,这些事情必须考虑好,做好数据的备份和存储
- 系统复杂性可能提高了,需要考虑消息是否被重复消费,消息处理是否丢失,消息传递的顺序性的等问题
- 关于一致性问题,消息队列实现异步提高系统的性能,但需要考虑到消息是否被真正的消费者正确消费,导致数据不一致的问题。
7. MyISAM和InnoDB的区别
- MyISAM缓存中有meta-data记录行数,而InnoDB则没有,因此MyISAM的COUNT(*)计算速度比InnoDB快
- MyISAM不支持事务,强调性能,查询具有原子性,速度比InnoDB快;InnoDB支持事务,提供commit,rollback,崩溃修复功能的事务安全型表
- InnoDB支持外键,MyISAM不支持
MyISAM用在读更密集的表,InnoDB更适合写密集的表。需要事务,较高并发读取频率则选择InnoDB(因为MyISAM不支持事务,且表锁的粒度过大,并发量大时,查询时间会很长)
8. ArrayList与LinkedList
- 两者都是不同步的,不保证线程安全
- ArrayList底层采用数组实现, LinkedList底层采用双向链表数据结构
- 插入和删除:ArrayList插入和删除都会受数据元素的位置影响;LinkedList的删除则不受元素位置影响
- ArrayList实现RandomAccess接口,实现随机元素访问(其原因和其底层实现有关),而Linked不支持随机访问
- ArrayList会预先占用部分空间,相对浪费一些空间;而LinkedList存储的对象占用的空间会更多,因为双向链表还需要存储直接后继和前驱
这里有个小技巧:
实现RandomAccess接口的List,优先选择普通for循环,其次用foreach;
未实现RandomAccess接口的List,优先选择使用iterator遍历,对于数据量很大的List,尽量少用普通for循环。